Dimensional Reduction
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How can we perform unsupervised learning with dimensionality reduction techniques such as Principle Component Analysis (PCA) and t-distributed Stochastic Neighbor Embedding (t-SNE)?
Objectives
Recall that most data is inherently multidimensional
Understand that reducing the number of dimensions can simplify modelling and allow classifications to be performed.
Recall that PCA is a popular technique for dimensionality reduction.
Recall that t-SNE is another technique for dimensionality reduction.
Evaluate the relative peformance of PCA and t-SNE.
Dimensionality Reduction
Dimensionality reduction serves as a potent technique for analysing and visualising data sets, especially when dealing with high-dimensional data such as datasets or outputs from machine learning models. These methods effectively reduce the number of features in your data, which is crucial considering that visualising anything beyond two dimensions is challenging. For this section we will focus on two commonly used methods for dimensionally reducing your data, One being Principal Component analysis (PCA) a linear method and second t-SNE a non-parametric/ non-linear method.
Examine the dataset
Lets make some plots looking at each of our features, so we can see the distribution of our features.
> par(mfrow = c(2, 2))
> hist(iris$Sepal.Length, breaks = 20) ## histograms for each features
> hist(iris$Sepal.Width, breaks = 20)
> hist(iris$Petal.Length, breaks = 20)
> hist(iris$Petal.Width, breaks = 20)
Principle Component Analysis (PCA)
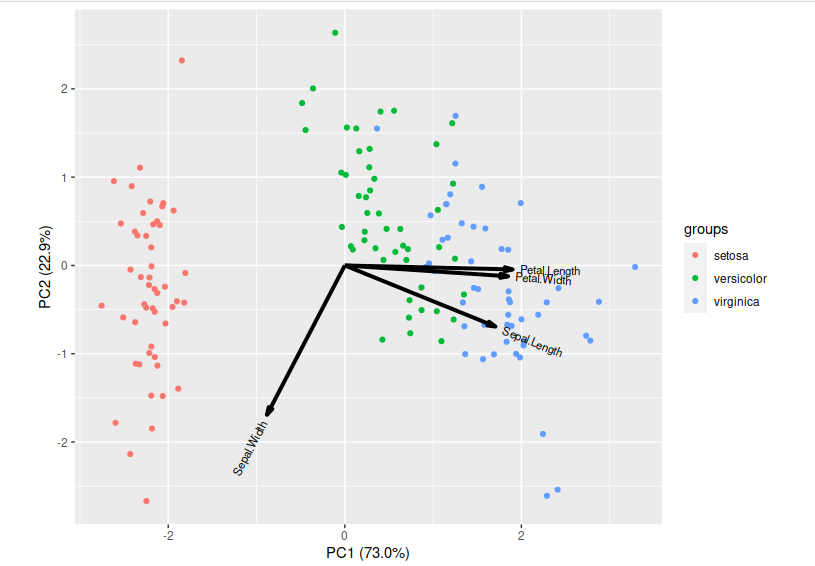
PCA is a technique that does rotations of data in a two dimensional array to decompose the array into combinations vectors that are orthogonal and can be ordered according to the amount of information they carry. As there are as many principal components as there are variables in the data, principal components are constructed in such a manner that the first principal component accounts for the largest possible variance in the data set. Hence, when you condense your data into two dimensions, you’re essentially utilising the two principal components characterised by the highest variance.
# PCA
# Make sure you reset your variables
> data(iris)
> pc <- prcomp(iris[,-5],center = T,scale. = T) ## start PCA
> pc
> summary(pc)
Standard deviations (1, .., p=4):
[1] 1.7083611 0.9560494 0.3830886 0.1439265
Rotation (n x k) = (4 x 4):
PC1 PC2 PC3 PC4
Sepal.Length 0.5210659 -0.37741762 0.7195664 0.2612863
Sepal.Width -0.2693474 -0.92329566 -0.2443818 -0.1235096
Petal.Length 0.5804131 -0.02449161 -0.1421264 -0.8014492
Petal.Width 0.5648565 -0.06694199 -0.6342727 0.5235971
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.7084 0.9560 0.38309 0.14393
Proportion of Variance 0.7296 0.2285 0.03669 0.00518
Cumulative Proportion 0.7296 0.9581 0.99482 1.00000
Now lets visualise our reduced features:
> library(ggbiplot)
> ggbiplot(pc,obs.scale = 1, var.scale = 1, groups = iris$Species) ##plot our pca results
t-distributed Stochastic Neighbor Embedding (t-SNE)
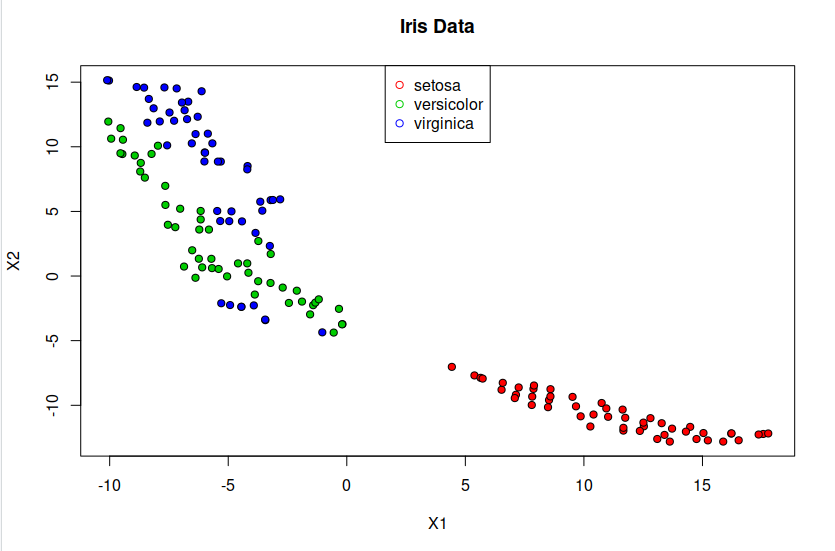
t-SNE is a statistical approach used to visually represent high-dimensional data by assigning each data point a position on a two- or three-dimensional map. Unlike linear techniques, t-SNE is nonlinear and is particularly effective for reducing the dimensionality of data to enable visualization in a lower-dimensional space. It accomplishes this by modeling each high-dimensional object as a point in two or three dimensions, ensuring that similar objects are positioned close together while dissimilar ones are placed farther apart with high probability.
# t-SNE embedding
> library(tsne)
> features <- subset(iris, select = -c(Species)) ### create a subset data frame without the species labels
> set.seed(0)
> tsne <- tsne(features, initial_dims = 2) ### lets reduce our features from 4 dimension to 2
> tsne <- data.frame(tsne) ## put it in data frame so its easier to use
> pdb <- cbind(tsne,iris$Species) ## add back in the labels
> summary(tsne)
X1 X2
Min. :-16.857 Min. :-5.276300
1st Qu.:-10.994 1st Qu.:-2.199154
Median : -2.691 Median : 0.009581
Mean : 0.000 Mean : 0.000000
3rd Qu.: 12.147 3rd Qu.: 2.051889
Max. : 20.724 Max. : 5.731033
> plot(tsne, pch=21, bg=c("red","green3","blue")[unclass(iris$Species)], main="Iris Data") ## plot tsne
> legend("top",levels(iris$Species), pch = 21, col = c("red","green3","blue"))
Exercise: Parameters
Look up parameters that can be changed in PCA and t-SNE, and experiment with these. How do they change your resulting plots? Might the choice of parameters lead you to make different conclusions about your data?
Exercise: Other Algorithms
There are other algorithms that can be used for doing dimensionality reduction, for example the Higher Order Singular Value Decomposition (HOSVD) Do an internet search for some of these and examine the example data that they are used on. Are there cases where they do poorly? What level of care might you need to use before applying such methods for automation in critical scenarios? What about for interactive data exploration?
Key Points
PCA is a linear dimensionality reduction technique for tabular data
t-SNE is another dimensionality reduction technique for tabular data that is more general than PCA